Today, we are releasing OpenThinker2-32B and OpenThinker2-7B, two new state of the art open-data reasoning models. Along with the models, we provide their training dataset OpenThoughts2-1M. Our models are simply trained with SFT on our curated data.
When we launched the OpenThoughts project, our goal was to build a SFT dataset in the open and train a DeepSeek-R1-Distill-Qwen-32B level reasoning model. We have now achieved that goal, averaged over our reasoning evaluations and we outperform DeepSeek-R1-Distill-Qwen-32B.
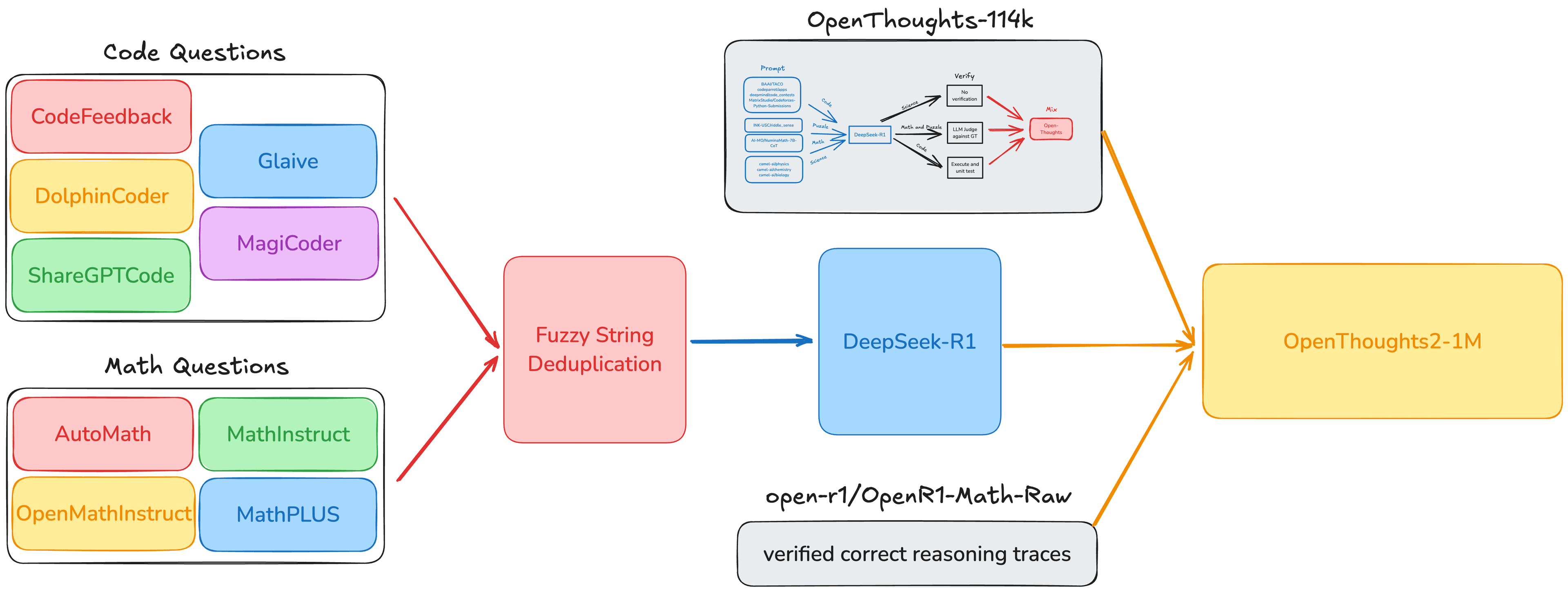
We used two approaches to create OpenThoughts2-1M by adding to OpenThoughts-114K:
- Leveraging existing reasoning data from the open source community
- Sourcing and generating new code and math reasoning data
Leveraging Existing Reasoning Data
The open source community has released a flurry of reasoning datasets in the last two months. We aimed to build on OpenThoughts-114K by adding new data from new external datasets to achieve a greater diversity and scale. We finetuned the Qwen2.5-7B-Instruct model on GeneralThought-430K, OpenR1-Math, Llama-Nemotron-Post-Training-Dataset-v1, SYNTHETIC-1, KodCode-V1 and measured downstream performance on our reasoning evaluation suite. Out of the datasets that we used in these experiments, we found that OpenR1-Math performed the best overall so we include it in OpenThoughts2-1M.
Generating New Reasoning Data
To further build upon the OpenThoughts-114K and OpenR1-Math mix, we generated additional math and code reasoning data. To do this, we try 26 different approaches for sourcing and generating math and code questions. For each strategy, we sample 5,000 questions, distill with DeepSeek-R1 and finetune Qwen-2.5-7B-Instruct on the resulting data.
To determine the best data sources, we measure the downstream performance of each model on relevant reasoning benchmarks. For code sources, we measure LiveCodeBenchV2. For math sources, we measure HumanEval, MATH500, AMC23, AIME24, GPQADiamond and LiveCodeBenchV2.
As seen in the tables above, the top performing math datasets are synthetic datasets from AutoMathInstruct, TigerLab, and Nvidia. We constructed AutoMathInstruct by searching for math related data within AutoMathText and using gpt-4o-mini to form related questions. The top performing code datasets are a mix of human coding questions (e.g. Code-290k-ShareGPT-Vicuna) and synthetic coding questions (e.g. CodeFeedback-Filtered-Instruction).
Using 30K questions from each of the top 5 data sources for code and 12.5k questions from each of the top 4 data sources for math on top of our OpenThoughts-114k + OpenR1-Math mix, we create our final OpenThoughts2-1M dataset.
OpenThoughts2-1M
OpenThoughts2 is a combination of OpenThoughts-114k, verified reasoning traces from OpenR1-Math, and the questions from our best math and code sources. This is visualized in the diagram below. Our full OpenThoughts2-1M dataset is released on HuggingFace. We will soon be adding the data generation code for OpenThoughts2-1M to our GitHub repository.
Evaluation Details
We evaluate OpenThinker2 on a set of popular reasoning benchmarks, running each benchmark multiple times (5x - AIME24, AIME25, AMC23 and 3x - LiveCodeBenchV2, GPQA-Diamond) and reporting the average accuracy. We set the temperature to 0.7 and the maximum token length to 32,768 during sampling. Our training datasets are decontaminated by removing samples with over 90% indel similarity against evaluation problems. All evaluations are conducted using our open-source framework Evalchemy, which we detailed in our previous post on reasoning evaluations.
Conclusion
OpenThoughts2-1M is a combination of OpenThoughts-114k, verified reasoning traces from OpenR1-Math, and our newly generated data. We finetune Qwen2.5-7B-Instruct and Qwen2.5-32B-Instruct on OpenThoughts2-1M to yield OpenThinker2-7B and OpenThinker2-32B. When compared with other reasoning models created from the same base, OpenThinker2-32B outperforms all other open-data models. Since all OpenThinker models have been trained only with SFT, we expect that RL post-training can further improve their performance.
We are excited for the research community to continue building together on these new reasoning models and datasets. If you have any questions or want to collaborate, feel free to raise an issue on our GitHub or reach out to us on X.