We release OpenThinker-32B, a state-of-the-art open-data reasoning model. We show that powerful reasoning models can be trained by scaling data, verifying reasoning traces, and scaling model size. OpenThinker-32B outperforms existing open-data reasoning models on a host of reasoning benchmarks including math, code, and science.
All reported numbers are computed using our open source evaluation framework Evalchemy. Note that R1-Distill-32B is a closed data model, which was finetuned from Qwen-2.5-32B-Instruct on a dataset of size 800k, reportedly containing 600k reasoning samples.
Data Curation
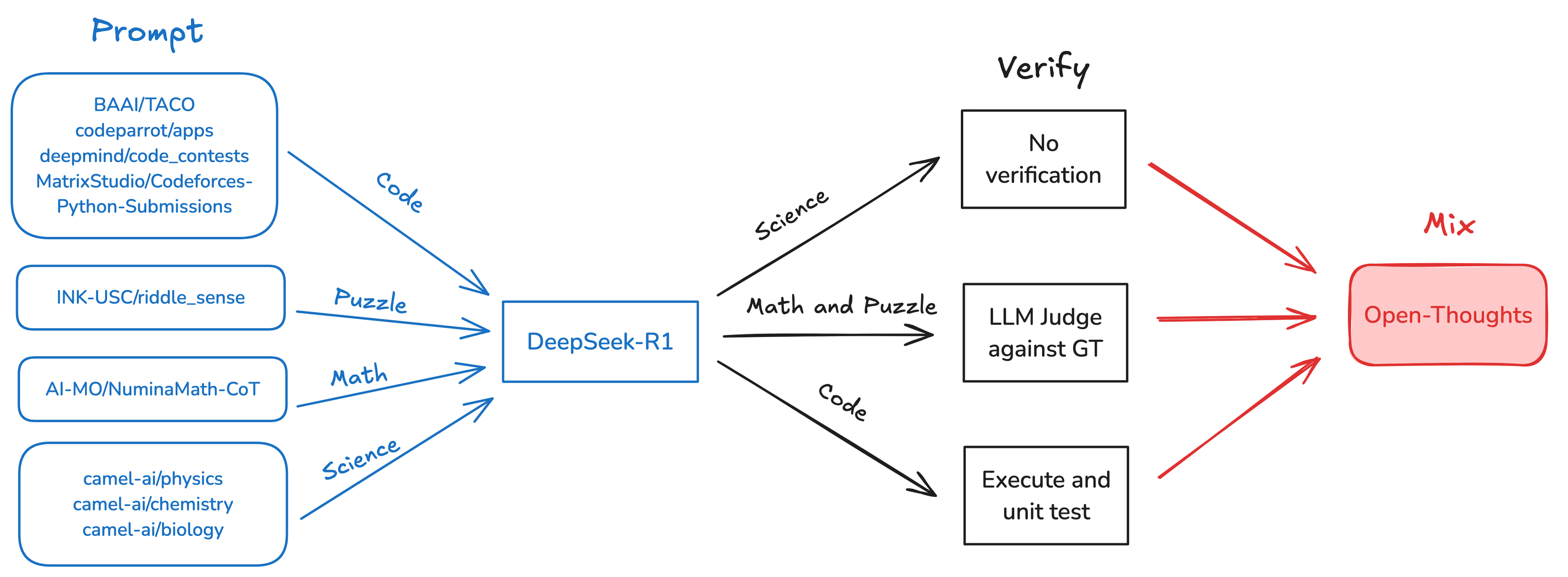
We train OpenThinker-32B on the same OpenThoughts-114k dataset as our earlier model OpenThinker-7B. Using DeepSeek-R1, we collected reasoning traces and solution attempts for a curated mix of 173k questions. We are now releasing this raw data as the OpenThoughts-Unverfied-173k dataset. The last step in the pipeline is filtering out samples if the reasoning trace fails verification. The full code which we used to construct our dataset is available on the open-thoughts GitHub repository.
As requested by the community, we have updated the final OpenThoughts-114k dataset to contain a "metadata" configuration that includes separate columns for:
problemground_truth_solutiontest_cases(code only)starter_code(code only)deepseek_reasoningdeepseek_solutiondomainsource
The additional metadata will make it easier to use this dataset in new ways such as filtering, swapping out domains, checking verification, and changing the reasoning trace templating.
load_dataset("open-thoughts/OpenThoughts-114k", "metadata", split="train")We are also excited to see the community use the problems and ground truth solutions for RL on top of the OpenThinker models, which DeepScaleR has shown to work particularly well at a smaller scale.
Verification
To obtain the final OpenThoughts-114k dataset, we verify the answers and eliminate incorrect responses. As shown below, keeping the reasoning traces that fail verification can harm performance, though the unverified model still performs well compared to other 32B reasoning models. Verification serves to maintain the quality of the R1 annotations while scaling up the diversity and size of the set of training prompts. On the other hand, unverified data can be scaled more easily, which makes it worth further exploring as well.
Reasoning traces for code problems are verified by checking the solution attempt against existing test cases. Inspired by the challenges faced during code execution, we implemented a code execution framework in Curator that enables users to scalably and securely execute code and verify against expected outputs. Math verification is determined by an LLM judge given the ground truth solution and DeepSeek-R1 solution attempt. We found that using an LLM judge instead of a stricter parsing engine (Math-Verify) for verification during data generation results in a higher yield and leads to higher performing downstream models.
Training
We finetune Qwen2.5-32B-Instruct on OpenThoughts-114k for 3 epochs with a 16k context length using LLaMa-Factory. Our full training configuration is provided in our repository. OpenThinker-32B was trained using four 8xH100 P5 nodes over a period of 90 hours, totalling 2,880 H100 hours on Toyota Research Institute's AWS SageMaker cluster. Meanwhile, OpenThinker-32B-Unverified was trained using 96 nodes of 4xA100 (64 GB per GPU) over a period of 30 hours, totaling 11,520 A100 hours on the Leonardo Supercomputer.
Evaluation
We evaluate all models using our open source evaluation library Evalchemy. For AIME24 and AIME25, we average the results of five runs to compute accuracy. Our evaluation configuration uses 0.7 as the temperature, restricts the model response to 32,768 tokens, does not add any additional system or user prompts and does not use any special decoding strategy (e.g. budget forcing).
When we launched the OpenThoughts project, we set a goal to create an open-data model that matches the performance of DeepSeek-R1-Distill-Qwen-32B. This gap is now almost closed. We are excited by the rapid progress in the community over the last few weeks in building open-data reasoning models and look forward to continuing building on each other's insights.