
Today, we are announcing OpenThoughts-Agent, an open-source effort to curate the best datasets for training agents. Our first release includes datasets, models and our research codebase; OpenThinker-Agent-v1 is the best model of its size on Terminal-Bench 2.0.
We built OpenThinker-Agent-v1 in two stages: supervised fine-tuning, followed by reinforcement learning. Each stage required its own data pipeline – RL tasks (instructions, environments, and verifiers) and SFT traces from strong teacher agents completing tasks.
Our first set of release artifacts are:
- OpenThinker-Agent-v1 Model
- SFT-only Model
- SFT Data (Traces)
- RL Data (Environments)
- Benchmark (OpenThoughts-TBLite)
- Benchmark (Dev Set v1)
- Codebase
OpenThoughts-Agent is an ongoing effort.
The next phase of our project involves iterating heavily on RL data recipes. We have built the training infra (integrating Harbor with SkyRL) for RL on the terminal bench format data. Join our public Discord to get involved.
Results
OpenThinker-Agent-v1 is the best model of its size on Terminal-Bench 2.0. It's also the best on our brand new Open-Thoughts-TB-Dev benchmark, curated especially for this project (see our evals section for more). These benchmarks are historically very hard for small models, with even Qwen3-8B, generally a very strong model on benchmarks, achieving low accuracy.
This is just the first step. In the near future, we plan to train more models on more data, start working with larger models and MoEs, and experiment with more sophisticated data pipelines.
Supervised Finetuning
We are excited to release OpenThoughts-Agent-v1-SFT, our first official OpenThoughts-Agent dataset! OpenThoughts-Agent-v1-SFT is an SFT trace dataset containing approximately 15,000 traces drawn from two different data sources we curate: NL2Bash (simple synthetically generated tasks where the agent has to format shell commands effectively) and InferredBugs is a set of bugs in C# and Java collected by Microsoft that we turned into tasks.
See our exemplar InferredBugs data generation script here.
SFT Data - Instruction Sourcing
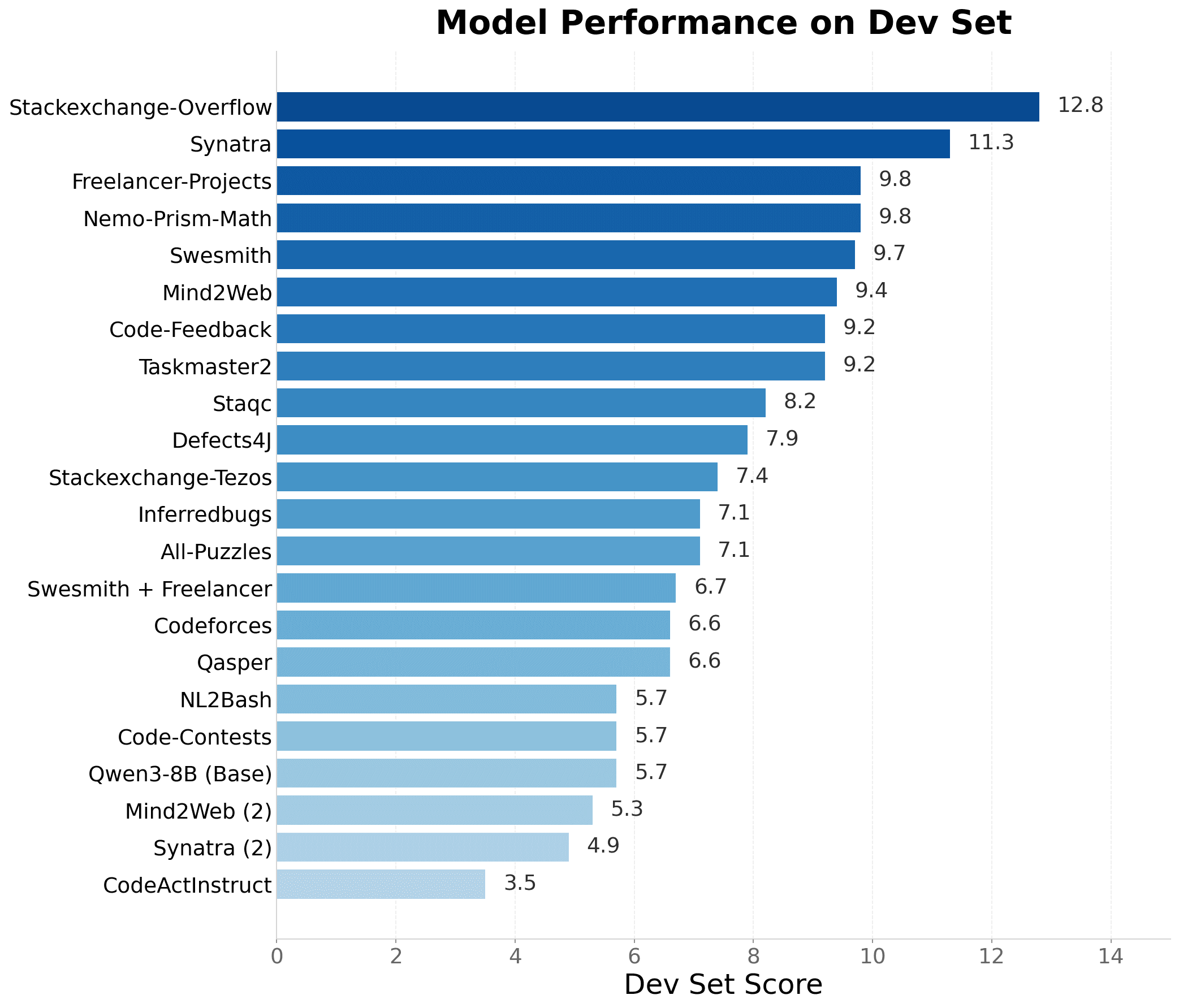
We define a task as a triplet of an instruction in the form of a markdown file, an environment defined by a DockerFile, and a verifier in the form of pytests (following Harbor). The verifier is not necessary for SFT data generation. All of our environments in this release are generic Ubuntu DockerFiles. To find the best way to generate instructions, we ablated 15 different approaches, selecting from both existing sources such as Nemo, SWESmith and Mind2Web, and those we created, such as StackExchange Overflow, Freelancer and Taskmaster. For each source, we generate approximately 10,000 tasks and let GPT-5-Nano solve each task once, resulting in a ~10,000 trace SFT dataset. We then evaluated each model on our new development set: OpenThoughts-TB-Dev.
SFT Data - Teacher Model
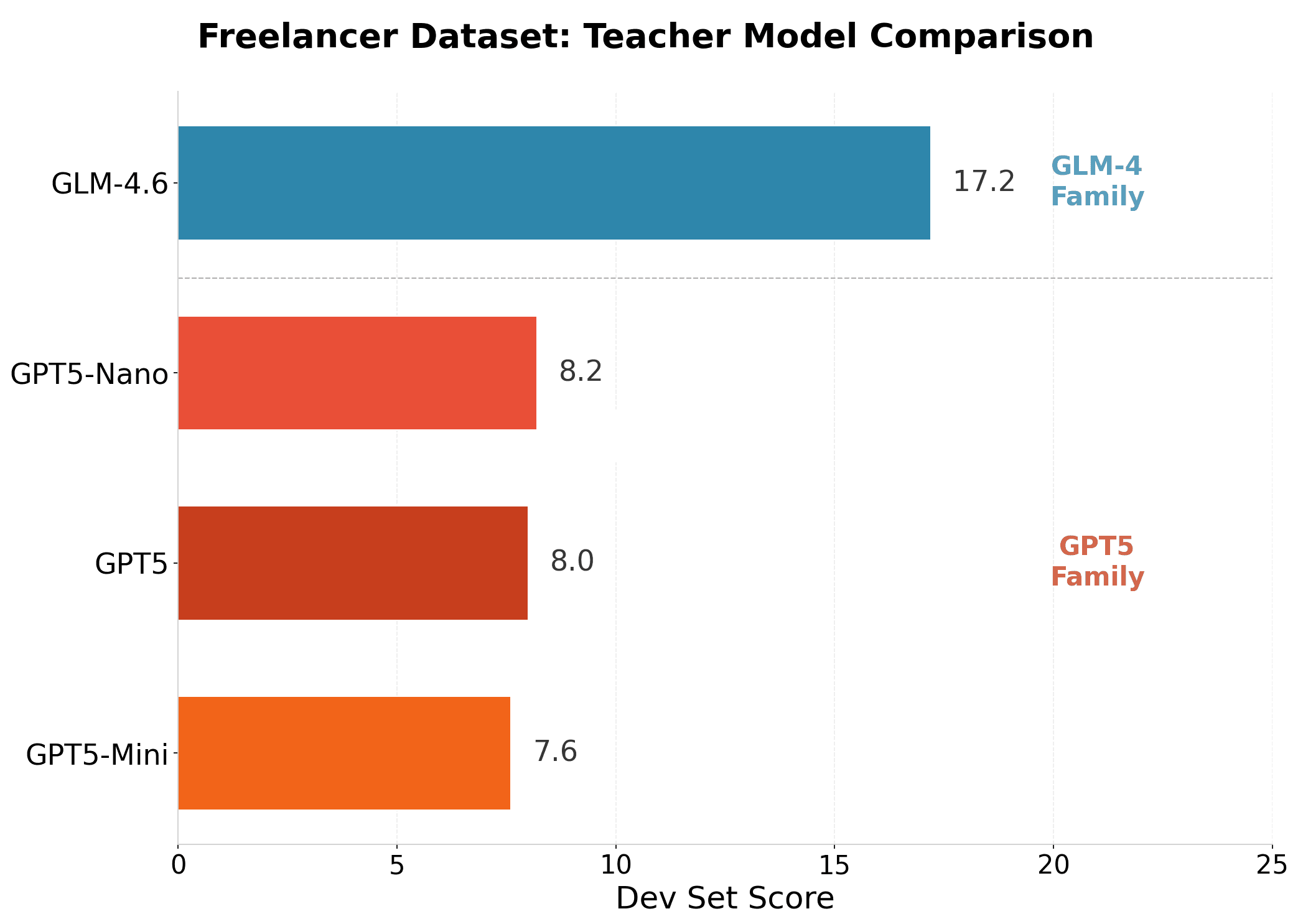
The second design choice we ablated was the choice of teacher. One would expect that the better the teacher model is on TerminalBench, the better it performs; surprisingly, we find that this is not the case. Rather, varying teachers in the GPT model family did not improve performance. However, using GLM-4.6 as a teacher led to almost a 2x improvement in downstream score.
SFT Training
Similar to OpenThoughts, the OpenThoughts-Agent SFT pipeline utilizes a fork of the popular Llama-Factory framework. Because we knew we would be training a lot of models, we paid a great deal of attention to optimizing our SFT pipeline to make it as efficient and precise as possible – to paraphrase Yejin Choi and Deadpool, we aimed for "maximum effort" SFT! We will say more about this optimization in a future release.
Reinforcement Learning
RL is a key part of the next phase of the OpenThoughts-Agent project. We have built an RL training stack by integrating SkyRL with Harbor and stress-tested it with a large number of RL runs on TerminalBench-style tasks. Conducting RL on our SFT-only model using our RL data, OpenThoughts-Agent-v1-RL, we get a small improvement on our development set of around ~2% and an improvement of 1% on SWE-Bench verified.
RL Data
Our data is NL2Bash with synthetically generated tasks. Our first step is to generate the instructions for the tasks; these are seeded from the original NL2Bash dataset, which consists of human-authored queries in natural language and human-authored bash commands (find, grep, etc) that fulfill the queries. In our dataset, both instructions and commands are permuted by a synthetic data generation model (GPT-5 Mini). The same model also writes tests and runs its own tests in a Daytona sandbox, confirming task quality. Finally, the model-generated task is extracted from the cloud sandbox and added to the dataset. Since this process is necessarily sometimes erratic, we subsequently verify correctness of the tasks and verifiers by removing any tasks GPT-5-Codex gets zero reward on. This results in a set of approximately 700 tasks (from 10,000 originally generated tasks).
As seen in the above table, doing RL on NL2Bash improves slightly over our base SFTed model. The code for generating our RL dataset is coming soon! We are excited to create new RL datasets that create even larger improvements on our benchmarks.
Evaluation
Because Terminal-Bench 2.0 is calibrated for frontier models, small open-source models tend to struggle to get any meaningful score. In other words, Terminal-Bench 2.0 isn't the ideal benchmark for marking incremental progress on small models. Fortunately, under the supervision of Mike Merrill, Alex Shaw and Negin Raoof, and with the help of dozens of volunteer contributors as well as Bespoke Labs, we were able to curate OpenThoughts-TB-Dev, a set of 70 new tasks for terminal agents. OpenThoughts-TB-Dev strongly correlates with Terminal-Bench 2.0, but it's considerably easier, making it possible for even small models to show meaningful signal.
Agentic evals are notoriously tough to interpret because of their long rollouts and highly technical content; to make our jobs easier, we produced an SFT trace viewer. It also works for RL tasks! You can use this with any of our eval or trace generation repositories to help parse and interpret the traces.
We also maintain a live leaderboard tracking the 300+ models we have trained so far; if you are interested in training your own models and seeing them on our leaderboard, all you need to do is join our Discord and share the public link to your model on HF.
Build with Us!
This is not the end of the road; it's just our first signpost. As a project based on radical collaboration and openness, we need your support as we race towards the finish line.
Open Thoughts is a collaboration led by universities and institutes, including Stanford, UC Berkeley, UT Austin, NYU, UW, UCLA, UNC, TUM, and LAION, clusters like JSC, TACC, ALCC Perlmutter, ZIH, Oumi Exun by Lambda, and a host of supporters in the startup community, including Daytona.io, Laude Institute, Bespoke Labs and Oumi.ai.
Join our Discord to get involved!
Citation
@misc{openthoughts-agent,
author = {Team, OpenThoughts-Agent},
month = Dec,
title = {{OpenThoughts-Agent}},
howpublished = {https://www.open-thoughts.ai/blog/agent},
year = {2025}
}